#include<iostream> usingnamespace std; constint N = 1e6 + 10 ;//一后面6个零,应该是1e6 + 10 int n; int q[N]; voidquick_sort(int q[], int l, int r) { if (l >= r) return; int x = q[(l + r) / 2], i = l - 1, j = r + 1; // 注意快速排序这道题目的数据已加强,划分中点取左端点或右端点时会超时,改成取中点或者随机值即可。 // 每次交换玩指针都要往中间移动一格, // 因此后面循环是这样做的, // 每次不管三七二十一, // 先把指针往中间移动一格, // 然后再去判断,因此两个指针都要放在左右两个边界的左右一格, // 这样我们往中间移动一格之后才是真正的边界 // 所以才有一个偏移量,需要往两边扩一格 // int x = q[(l + r) / 2]; // int x = q[r]; while (i < j) { do i++; while (q[i] < x); do j--; while (x < q[j]); if (i < j) swap(q[i], q[j]); }
quick_sort(q, l, j); quick_sort(q, j + 1, r); } intmain(void) { scanf("%d", &n); for (int i = 0; i < n; i++) scanf("%d", &q[i]);
quick_sort(q, 0, n - 1);
for (int i = 0; i < n; i++) printf("%d ", q[i]); return0; }
#include<iostream> usingnamespace std; constint N = 1e6 + 10; int n; int q[N]; voidquick_sort(int q[], int l, int r) { if (l >= r) return; int x = q[(l + r) / 2], i = l - 1, j = r + 1; while (i < j) { do i++; while (q[i] < x); do j--; while (x < q[j]); if (i < j) swap(q[i], q[j]); }
quick_sort(q, l, j); quick_sort(q, j + 1, r); } intmain(void) { scanf("%d", n);//错误 for (int i = 0; i < n; i++) { scanf("%d", &q[i]); } quick_sort(q, 0, n - 1);
for (int i = 0; i < n; i++) { printf("%d ", q[i]); } return0; }
#include<iostream> usingnamespace std; constint N = 100010; int n; int q[N]; voidquick_sort(int q[], int l, int r);
intmain(void) { scanf("%d", &n); for (int i = 0; i < n; i++) scanf("%d", &q[i]); quick_sort(q, 0, n - 1); for (int i = 0; i < n; i++) printf("%d ", q[i]); return0; } voidquick_sort(int q[], int l, int r) { if (l >= r) return; // 这是一个疑点,我认为是l >= r 的原因是当l == r的时候一个元素组成的序列就是有序的,所以你不用再递归下去了,这就是最后一层递归了,直接返回上一层就行 int x = q[(l + r) / 2], i = l - 1, j = r + 1; // 个人记忆口诀,快排和归并排序都用到i和j来对数组q[] 的当下这一层递归的部分 也就是l 到 r这一部分进行处理 // 同时不能改变l 和 r的值,因为要作为实参传给下一层递归,所以用借用i和j // 二分查找就不需要i和j,因为直接在while循环里面更新l = mid或者 r = mid来让区间缩小 while (i < j) { // 个人记忆口诀,对于快拍而言,因为这个while循环条件是i < j,所以递归终止条件是if (i >= j) do i++; while (q[i] < x); do j--; while (q[j] > x); if (i < j) // 不能忘了这个if,因为很可能你找到i和j后就已经不满足i < j的条件了, // 我记得y总一开始举的数组序列的例子就是第一次找到的i和j之后,发现i >= j了 swap(q[i], q[j]); }
quick_sort(q, l, j); quick_sort(q, j + 1, r); }
疑点1
1 2
if (l >= r) return; // 这是一个疑点,我认为是l >= r 的原因是当l == r的时候一个元素组成的序列就是有序的,所以你不用再递归下去了,这就是最后一层递归了,直接返回上一层就行
查找第一次写的代码就是if(l >= r),个人认为的原因就是我上面的注释
疑点2
1 2 3 4 5 6
int x = q[(l + r) / 2], i = l - 1, j = r + 1; // 个人记忆口诀,快排和归并排序都用到i和j来对数组q[] 的当下这一层递归的部分 也就是l 到 r这一部分进行处理 // 同时不能改变l 和 r的值,因为要作为实参传给下一层递归,所以用借用i和j // 二分查找就不需要i和j,因为直接在while循环里面更新l = mid或者 r = mid来让区间缩小 while (i < j) { // 个人记忆口诀,对于快拍而言,因为这个while循环条件是i < j,所以递归终止条件是if (i >= j)
疑点3
1 2 3 4
if (i < j) // 不能忘了这个if,因为很可能你找到i和j后就已经不满足i < j的条件了, // 我记得y总一开始举的数组序列的例子就是第一次找到的i和j之后,发现i >= j了 swap(q[i], q[j]);
constint N = 100010; int n; int q[N]; voidquick_sort(int q[], int l, int r); intmain(void) { scanf("%d", &n); for (int i = 0; i < n; i++) { scanf("%d", &q[i]); } quick_sort(q, 0, n - 1); for (int i = 0; i < n; i++) { printf("%d ", q[i]); } return0; } voidquick_sort(int q[], int l, int r) { if (l >= r) return; int x = q[(l + r) / 2], i = l - 1, j = r + 1; while (i < j) { do i++; while (q[i] < x); do j--; while (q[j] > x); if (i < j) swap(q[i], q[j]); } quick_sort(q, l, j); quick_sort(q, j + 1, r); }
最后一个记忆口诀:就是==第一次记忆的就是用到int x = q[(l + r ) / 2],然后是j.直接记忆就行了==.
==同理直接记忆用i - 1 替换j的话,就直接写成int x = q[(l + r + 1) / 2];==
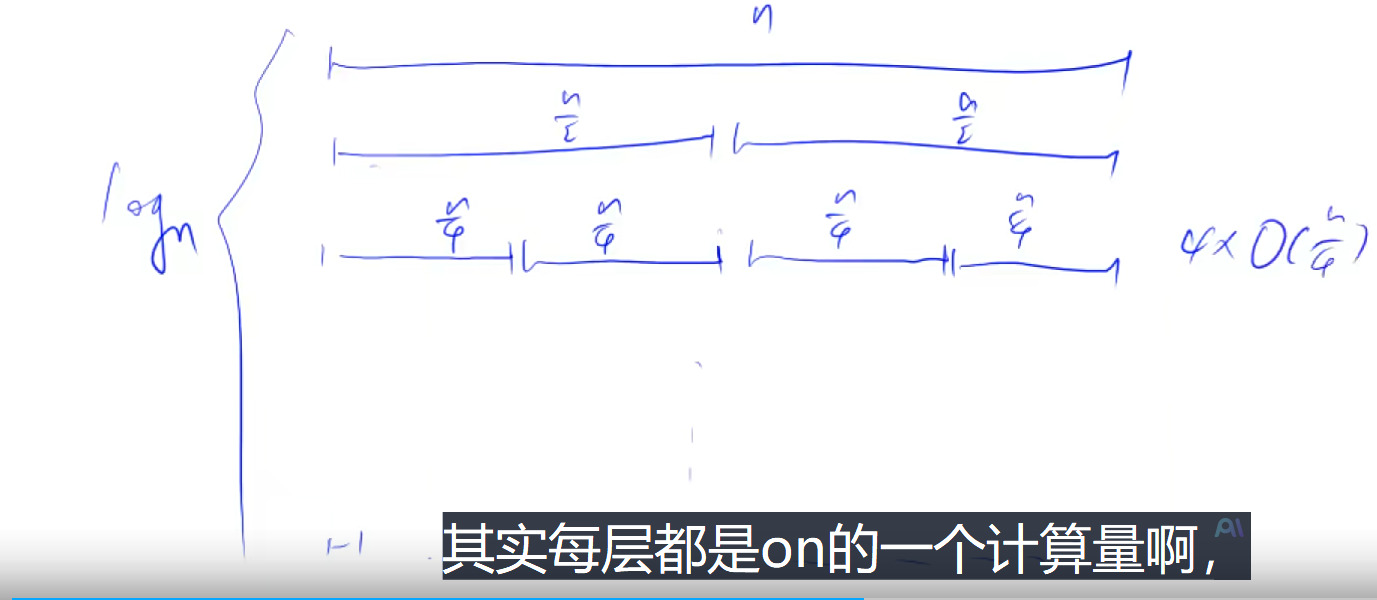
#include<iostream> usingnamespace std; constint N = 1000010; int n; int q[N], tmp[N]; voidmerge_sort(int q[], int l, int r) { if (l >= r) return; int mid = l + r >> 1; merge_sort(q, l, mid); merge_sort(q, mid + 1, r);
int k = 0, i = l, j = mid + 1; // k表示当前辅助数组tmp里面有多少个数了,已经合并多少个数了 // i指向第一个序列的起点 // j指向第二个序列的起点 while (i <= mid && j <= r) { if (q[i] <= q[j]) tmp[k++] = q[i++]; else tmp[k++] = q[j++]; } while (i <= mid) tmp[k++] = q[i++]; while (j <= r) tmp[k++] = q[j++];
for (i = l, j = 0; i <= r; i++, j++) q[i] = tmp[j]; } intmain(void) { scanf("%d", &n); for (int i = 0; i < n; i++) { scanf("%d", &q[i]); } merge_sort(q, 0, n - 1); for (int i = 0; i < n; i++) { printf("%d ", q[i]); } return0; }
七次
1103第一次
犯的错误1
1
int mid = l + r >> 2;//写错了,应该是右移一位等于除以2
应该写成
1
int mid = l + r >> 1;//写错了,应该是右移一位等于除以2
犯的错误2
1 2 3 4 5
while (i <= mid && j <= r) if (q[i] < q[j])//q[i] <= q[j] tmp[k++] = q[i++]; else tmp[k++] = q[j++];
为了保证归并的稳定性,应该写成
1 2 3 4 5
while (i <= mid && j <= r) if (q[i] <= q[j])//q[i] <= q[j] tmp[k++] = q[i++]; else tmp[k++] = q[j++];
#include<iostream> usingnamespace std; constint N = 1000010;//写错了,应该少些一个0 int n; int q[N], tmp[N]; voidmerge_sort(int q[], int l, int r) { if (l >= r) return; int mid = l + r >> 2;//写错了,应该是右移一位等于除以2 merge_sort(q, l, mid); merge_sort(q, mid + 1, r); int k = 0, i = l, j = mid + 1; while (i <= mid && j <= r) if (q[i] <= q[j]) tmp[k++] = q[i++]; else tmp[k++] = q[j++]; while (i <= mid) tmp[k++] = q[i++]; while (j <= r) tmp[k++] = q[j++]; for (int i = l, j = 0; i <= r; i++, j++)//这个不能忘,是将临时数组里面的所有数都存回q里面去. q[i] = tmp[j]; } intmain(void) { scanf("%d", &n); for (int i = 0; i < n; i++) { scanf("%d", &q[i]); } merge_sort(q, 0, n - 1); for (int i = 0; i < n; i++) { printf("%d ", q[i]); } return0; }
#include<iostream> usingnamespace std; constint N = 100010; int n; int q[N], tmp[N]; voidmerge_sort(int q[], int l, int r); intmain(void) { scanf("%d", &n); for (int i = 0; i < n; i++) scanf("%d", &q[i]); merge_sort(q, 0, n - 1); for (int i = 0; i < n; i++) printf("%d ", q[i]); return0; } voidmerge_sort(int q[], int l, int r) { if (l >= r) return; int mid = l + r >> 1; merge_sort(q, l, mid); merge_sort(q, mid + 1, r); int k = 0, i = l, j = mid + 1; while (i <= mid && j <= r) { if (q[i] <= q[j]) tmp[k++] = q[i++]; else tmp[k++] = q[j++]; } while (i <= mid)
tmp[k++] = q[i++]; while (j <= r) tmp[k++] = q[j++]; for (i = l, j = 0; i <= r; i++, j++) q[i] = tmp[j]; }
第一个疑点
1
int mid = l + r >> 1;
还是
1
int mid = (l + r) / 2;
其实两个都是可以的, 但是y总写的时候是第一个,我个人认为第一个没有括号更好写,所以我也写第一个
第二个疑点
1 2
for (i = l, j = 0; i <= r; i++, j++) q[i] = tmp[j];
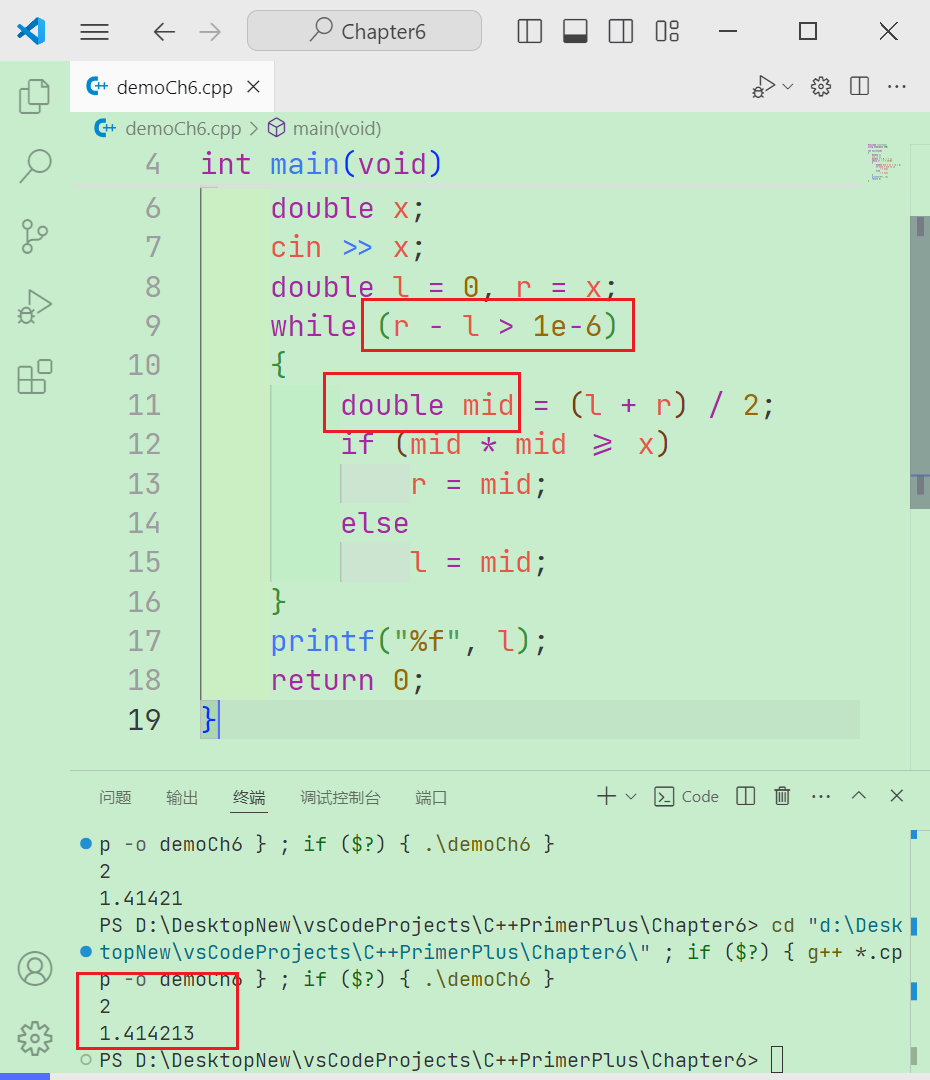
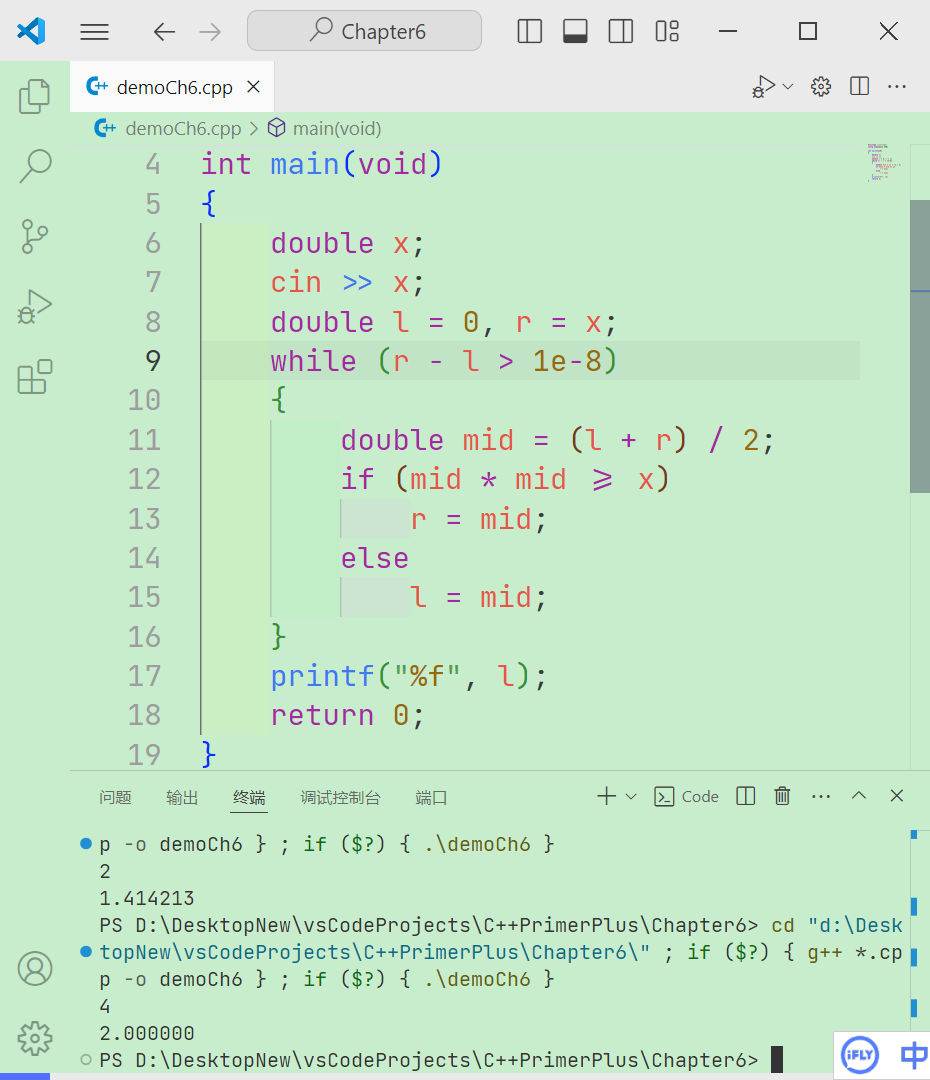
// 区间[l, r]被划分成[l, mid]和[mid + 1, r]时使用 intbsearch_1(int l, int r) { while (l < r) { int mid = l + r >> 1; if (check(mid)) r = mid; else l = mid + 1; } return l; }
// 区间[l, r]被划分成[l, mid - 1]和[mid, r]时使用 intbsearch_2(int l, int r) { while (l < r) { int mid = l + r + 1 >> 1; // 最核心的区别 if (check(mid)) l = mid; else r = mid - 1; } return l; }
// 区间[l, r]被划分成[l, mid]和[mid + 1, r]时使用 intbsearch_1(int l, int r) { while (l < r) { int mid = l + r >> 1; if (check(mid)) r = mid; else l = mid + 1; } return l; }
// 区间[l, r]被划分成[l, mid - 1]和[mid, r]时使用 intbsearch_2(int l, int r) { while (l < r) { int mid = l + r + 1 >> 1; // 最核心的区别 if (check(mid)) l = mid; else r = mid - 1; } return l; }
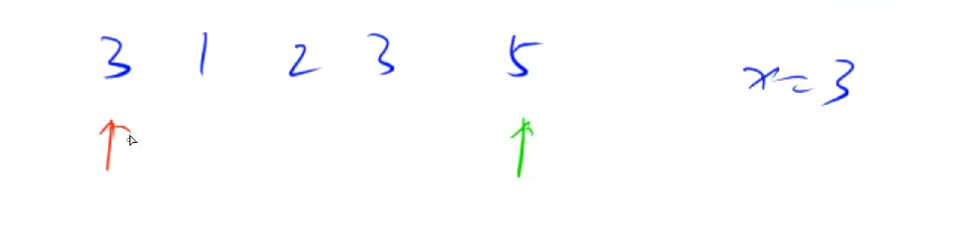
#include<iostream> usingnamespace std; constint N = 100010; int n; int q[N]; // 记录自己每一次不太确定的部分,好像是N,不是n boolcheckStart(int mid, int k); intbsearchStart(int q[], int l, int r, int k); boolcheckEnd(int mid, int k); intbsearchEnd(int q[], int l, int r, int k); intmain(void) { int m; // m表示询问次数 scanf("%d %d", &n, &m); // 差点忘记给n和m加上引用符号 for (int i = 0; i < n; i++) scanf("%d", &q[i]); int k; // 要查询的元素 while (m--) { scanf("%d", &k); int startIndex = bsearchStart(q, 0, n - 1, k); int startEnd = bsearchEnd(q, 0, n - 1, k); cout << startIndex << " " << startEnd << endl; }
return0; }
boolcheckEnd(int mid, int k) { if (q[mid] <= k) returntrue; // 红色分界点就是从右往左第一个小于等于k的数字,就是题干要我们找的答案之二,就是数字k的结束位置 else returnfalse; } boolcheckStart(int mid, int k) { if (q[mid] >= k) returntrue; // 绿色分界点就是第一个大于等于k的数字,就是题干要我们找的答案之一,就是数字k的开始位置 else returnfalse; } intbsearchStart(int q[], int l, int r, int k) {
while (l < r) { // 应该是l < r不带等号,因为要保证循环结束的时候l == r从而区间里面只有一个数,这个数就是我们要找的答案,就是红绿区间分界点 int mid = l + r >> 1; // mid应该在while里面,不然每一次循环mid都一直是最开始的l和最开始的r的和的一半 if (checkStart(mid, k)) r = mid; // 既然是r = mid就不用让mid = l + r + 1 >> 1 else l = mid + 1; } if (q[l] != k) // 这是因为题干要求而在模板基础上做的改变. return-1; // 如果q[l] != k,说明这个数字q[]里面没有数值等于k 的数字,不存在该元素,就返回 -1 else return l; } intbsearchEnd(int q[], int l, int r, int k) {
while (l < r) { // 应该是l < r不带等号,因为要保证循环结束的时候l == r从而区间里面只有一个数,这个数就是我们要找的答案,就是红绿区间分界点 int mid = l + r + 1 >> 1; // mid应该在while里面,不然每一次循环mid都一直是最开始的l和最开始的r的和的一半 if (checkEnd(mid, k)) l = mid; // 既然是l = mid就必要让mid = l + r + 1 >> 1 else r = mid - 1; } if (q[l] != k) // 这是因为题干要求而在模板基础上做的改变. return-1; // 如果q[l] != k,说明这个数字q[]里面没有数值等于k 的数字,不存在该元素,就返回 -1 else return l; }
写的时候的疑点:
第一个疑点
int q[N]; // 记录自己每一次不太确定的部分,好像是N,不是n
这里就是N,N表示数组的最大空间是MAX
n是你输入的元素个数,是size
第二个疑点
int bsearchStart(int q[], int l, int r, int k);和int bsearchEnd(int q[], int l, int r, int k);不用传数组int q[]因为你已经把他定义成全局变量了.只用传入数组的开始下标0,数组的结束下标n - 1,要查询的数字k
#include<iostream> usingnamespace std; constint N = 100010; int n; int q[N]; boolcheckStart(int mid, int k); boolcheckEnd(int mid, int k); intbsearchStart(int l, int r, int k); intbsearchEnd(int l, int r, int k); intmain(void) { int m;
cin >> n >> m; for (int i = 0; i < n; i++) scanf("%d", &q[i]);
while (m--) { int k; cin >> k; int indexStart = bsearchStart(0, n - 1, k); int indexEnd = bsearchEnd(0, n - 1, k); cout << indexStart << " " << indexEnd << endl; } return0; } boolcheckStart(int mid, int k) { if (q[mid] >= k) returntrue; else returnfalse; } boolcheckEnd(int mid, int k) { if (q[mid] <= k) returntrue; else returnfalse; } intbsearchStart(int l, int r, int k) { while (l < r) { int mid = l + r >> 1; if (checkStart(mid, k)) r = mid; else l = mid + 1; } if (q[l] != k) return-1; else return l; } intbsearchEnd(int l, int r, int k) { while (l < r) { int mid = l + r + 1 >> 1; if (checkEnd(mid, k)) l = mid; else r = mid - 1; } if (q[l] != k) return-1; else return l; }
#include<iostream> usingnamespace std; constint N = 100010; int n; int m; // m表示询问个数 int q[N]; intfindStartIndex(int l, int r, int k); intfindEndIndex(int l, int r, int k); boolcheckForStartIndex(int mid, int k); boolcheckForEndIndex(int mid, int k);
intmain(void) { scanf("%d %d", &n, &m); for (int i = 0; i < n; i++) scanf("%d", &q[i]); // 有m个询问 while (m--) { int k; scanf("%d", &k); int startIndex = findStartIndex(0, n - 1, k); int endIndex = findEndIndex(0, n - 1, k); printf("%d %d\n", startIndex, endIndex); } return0; }
intfindStartIndex(int l, int r, int k) { // 粗略回忆一下,是通过不断地缩小要查找的区间从而最终找到目标的 while (l < r) // 这里是<还是<=自己已经忘记 了 { int mid = l + r >> 1; // 让左边的区间都是满足这个性质的,右边的区间都是不满足这个性质的 // 这里找元素 k的起始位置,那么这个元素k的起始位置就是我们的目标,也就是我们的分界点 // 元素k的右边,包括元素k都是>= k 的; 元素k的左边都是小于元素k的 // 如果q[mid]满足小于元素k的性质,那我们要在mid的右边去找我们的 分界点
// 一些记忆点, if里面都是更新l, else里面都是更新r // 让我回忆回忆 if (checkForStartIndex(mid, k)) l = mid + 1; // 因为mid指向的数一定小于k,所以不可能是mid指向的数 是 k的起始位置 else r = mid; } if (q[l] == k) return l; else return-1; } intfindEndIndex(int l, int r, int k) { // 粗略回忆一下,是通过不断地缩小要查找的区间从而最终找到目标的 while (l < r) { int mid = l + r + 1 >> 1; // 这里的记忆口诀是看常数的出现,上面函数出现的常数是+ 1, 所以不用在这里+1; 这个函数出现的常数是-1,所以就要在这里+ 1 // 让左边的区间都是满足这个性质的,右边的区间都是不满足这个性质的 // 这里找元素 k的终止位置,那么这个元素k的终止位置就是我们的目标,也就是我们的分界点 // 元素k的右边都是> k 的; 元素k的左边包括元素k都是<=元素k的 // 如果q[mid]满足<=元素k的性质,那我们要在mid的右边去找我们的 分界点
// 一些记忆点, if里面都是更新l, else里面都是更新r // 让我回忆回忆 if (checkForEndIndex(mid, k)) l = mid; // q[mid]满足<=元素k,那么q[mid]是有可能就是元素k的终止位置的 else r = mid - 1; } if (q[l] == k) return l; else return-1; } // 找到最左边的 k boolcheckForStartIndex(int mid, int k) { if (q[mid] < k) // 难道都找的是左边区间满足的性质么???? // 个人认为找左边区间满足的性质,这样true的情况就直接更新l.符合先l后r的习惯 returntrue; else returnfalse; } boolcheckForEndIndex(int mid, int k) { if (q[mid] <= k) // 难道都找的是左边区间满足的性质么???? returntrue; else returnfalse; }
第一个疑点
1
while (l < r) // 这里是<还是<=自己已经忘记 了
就是l<r,你就和快排一起学的,所以就和快排一起记忆,快排里面的就是递归终止条件是
1
if( l >= r) return;
快排后面的循环是while(i < j)
所以你也记住这里就是while(l < r)
第二个疑点
1 2
if (q[mid] < k) // 难道都找的是左边区间满足的性质么???? // 个人认为找左边区间满足的性质,这样true的情况就直接更新l.符合先l后r的习惯
#include<iostream> usingnamespace std; constint N = 100010; int n; int m; // m表示询问个数 int q[N]; intbsearchStart(int l, int r, int k); intbsearchEnd(int l, int r, int k); boolcheckStart(int mid, int k); boolcheckEnd(int mid, int k);
intmain(void) { scanf("%d %d", &n, &m); for (int i = 0; i < n; i++) scanf("%d", &q[i]); // 有m个询问 while (m--) { int k; scanf("%d", &k); int startIndex = bsearchStart(0, n - 1, k); int endIndex = bsearchEnd(0, n - 1, k); printf("%d %d\n", startIndex, endIndex); } return0; } intbsearchStart(int l, int r, int k) { // 元素k的起始位置,把它作为分界点,看左右区间的性质,按照y总的将有等于号的设定为性质,且返回true // 也就是元素k的右边,包括元素k都是>= k的 while (l < r) { int mid = l + r >> 1; if (checkStart(mid, k)) r = mid; else l = mid + 1; } if (q[l] == k) return l; else return-1; } intbsearchEnd(int l, int r, int k) { while (l < r) { int mid = l + r + 1 >> 1; // 把元素k的终止位置作为分界点,元素k的左边包括元素k都是<= k的,把这个作为check条件 if (checkEnd(mid, k)) l = mid; else r = mid - 1; } if (q[l] == k) return l; else return-1; } boolcheckStart(int mid, int k) { if (q[mid] >= k) returntrue; else returnfalse; } boolcheckEnd(int mid, int k) { if (q[mid] <= k) returntrue; else returnfalse; }