大数据技术原理与应用华为云实验实时分析
1.实验目的
l 掌握大数据相关服务的购买及基础配置
l 掌握使用Flume采集数据
l 掌握Flink SQL代码的编写
l 掌握使用DLV进行数据可视化
l 掌握实时流数据的处理流程
2.实验平台与服务
l MRS (MapReduce Service)
MapReduce服务是一个在华为云上部署和管理Hadoop系统的服务,一键即可部署Hadoop集群。
l DLI (Data Lake Insight)
数据湖探索是完全兼容Apache Spark、Apache Flink、openLooKeng(基于Apache Presto)生态,提供一站式的流处理、批处理、交互式分析的Serverless融合处理分析服务。
l RDS (Relational Database Service)
华为云关系型数据库是一种基于云计算平台的即开即用、稳定可靠、弹性伸缩、便捷管理的在线关系型数据库服务,支持单机和主备部署模式,支持MySQL、PostgreSQL、SQL Server等主流的关系型数据库引擎。
l CDM (Cloud Data Migration)
云数据迁移是提供同构/异构数据源之间批量数据迁移服务,帮助客户实现数据自由流动。
l DLV (Data Lake Visualization)
数据可视化是一站式数据可视化开发平台,提供丰富多样的2D、3D可视化组件,采用拖拽式自由布局,旨在帮助用户快速定制和应用属于自己的数据大屏。
3.实验步骤与结果
3.1.大数据相关服务的购买与基本配置
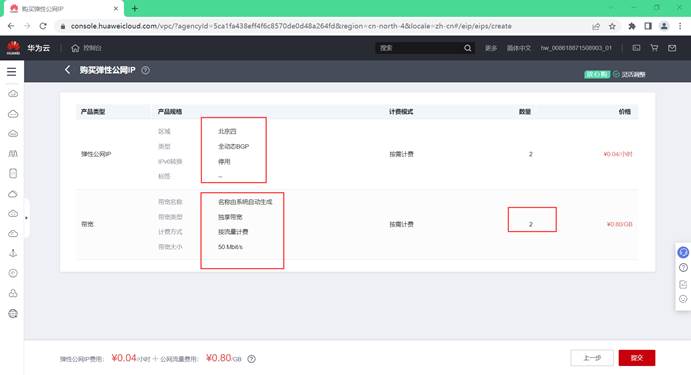
3.1.1.申请弹性公网ip

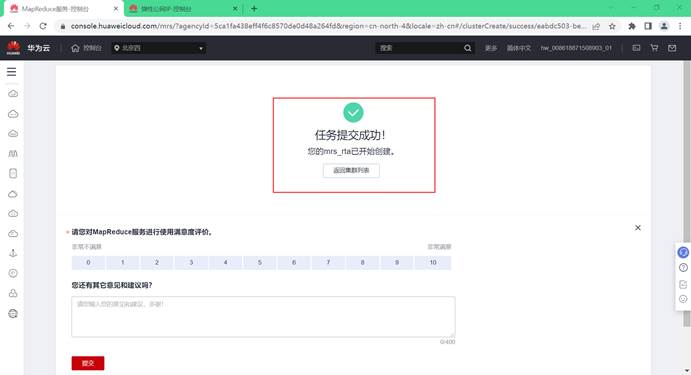
3.1.2.开通MapReduce服务



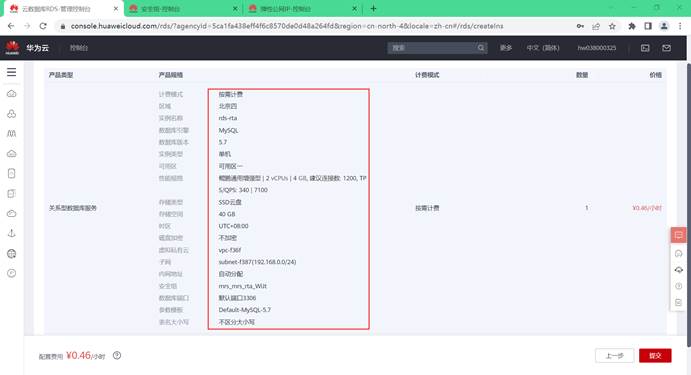
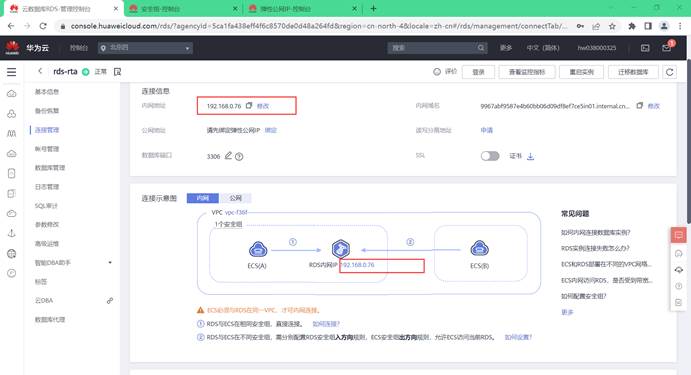
3.1.3.开通云数据库服务RDS

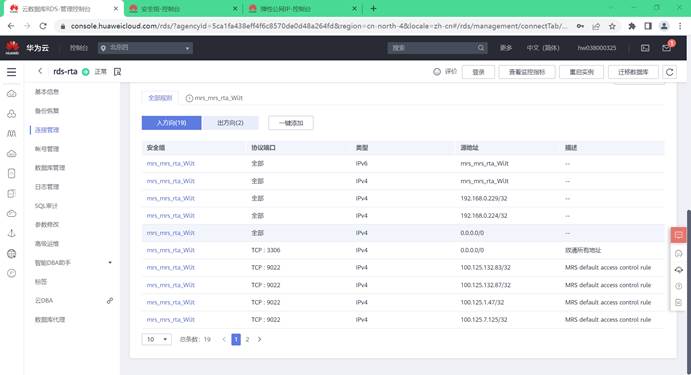
3.1.4.开通数据湖探索服务

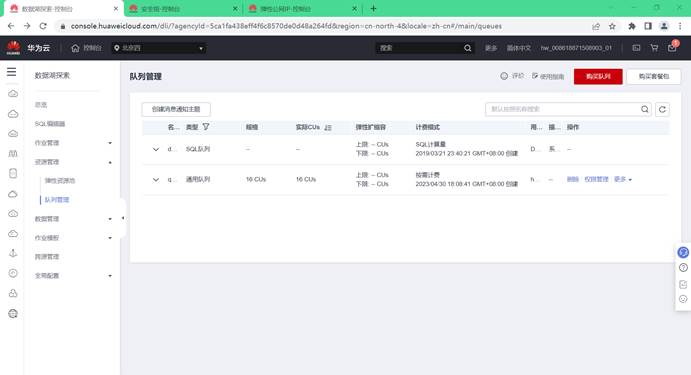
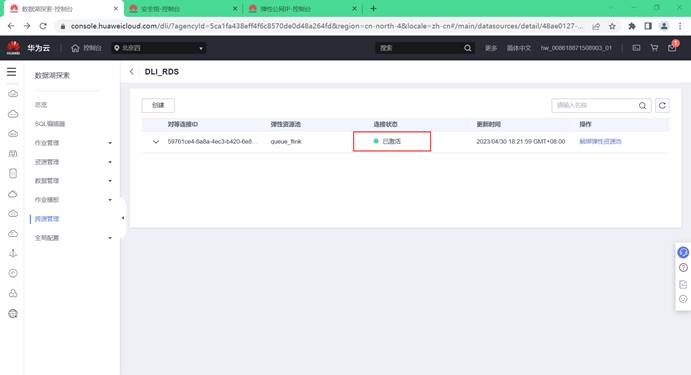
配置跨源链接


3.1.5.开通数据迁移服务CDM


3.1.6.开通数据可视化服务DLV
3.2.大数据实时数据分析开发实战
3.2.1.Python脚本生成测试数据
(1)执行Python命令,测试生成100条数据
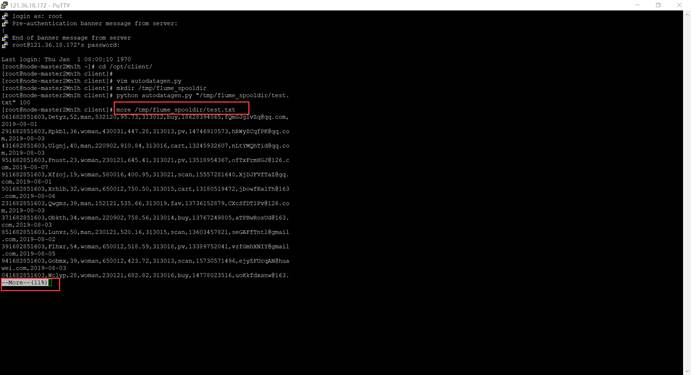
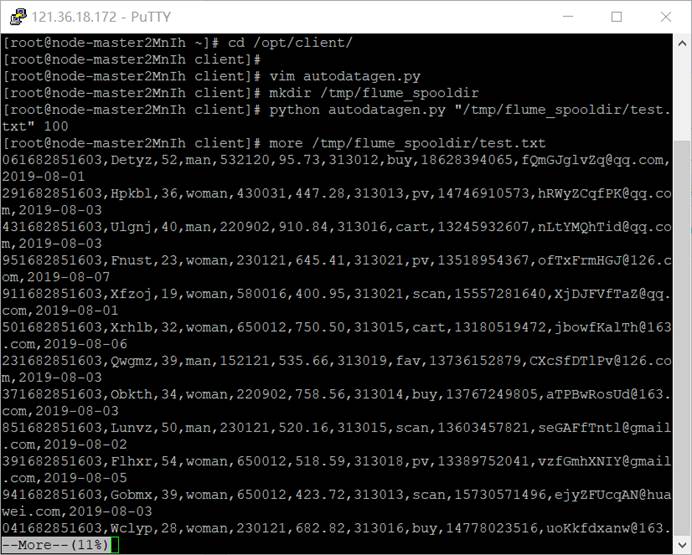
(2)使用more命令查看生成的数据。
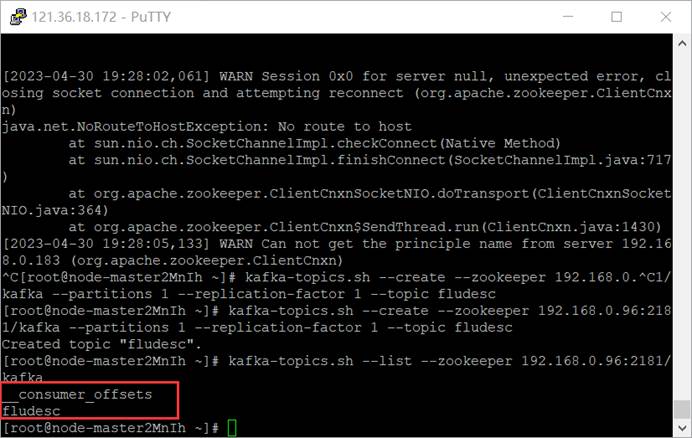
3.2.2.配置Kafka
(1)创建topic

(2)查看topic信息
3.2.3.安装Flume客户端
(1)进入到MRS Manager界面

下载完成后会有弹出框提示下载到哪一台服务器上(这台机器就是master节点),路径就是/tmp/MRS-client。

(2)校验下载的客户端文件包
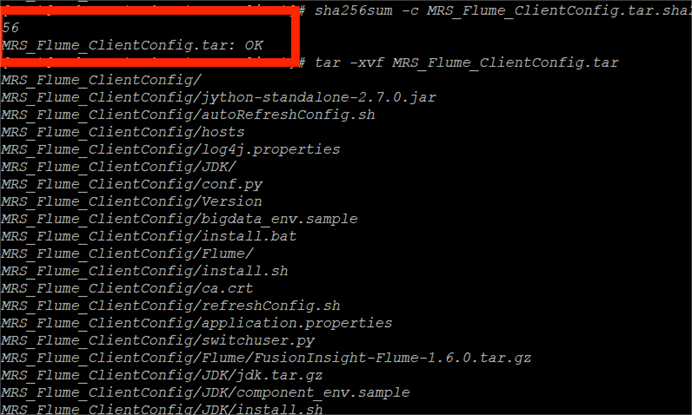
(3)安装Flume运行环境

3.2.4.配置Flume采集数据

3.2.5.MySQL中准备结果表和维度数据表
(1)新建数据库

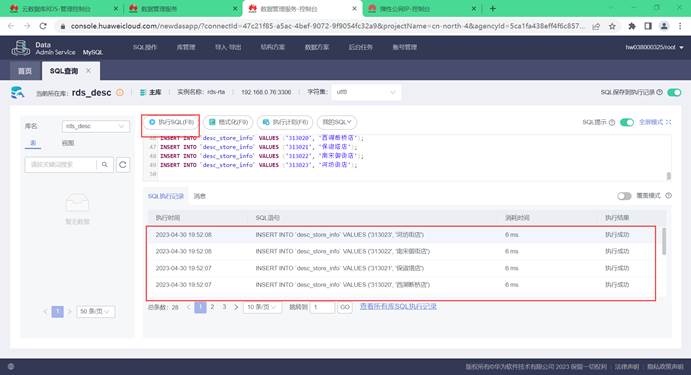
(2)执行SQL
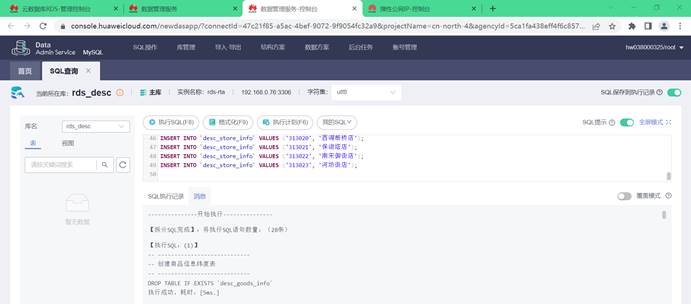
(3)创建数据表

3.2.6.使用DLI中的Flink作业进行数据分析
(1)编辑SQL并进行语义校验

(2)输入kafka_bootstrap_servers地址,测试连通性

(3)查看作业运行详情


(3)验证数据分析

3.2.7.DLV数据可视化
(1)展示销售额排行前5的门店信息

(2)定时执行数据生成脚本

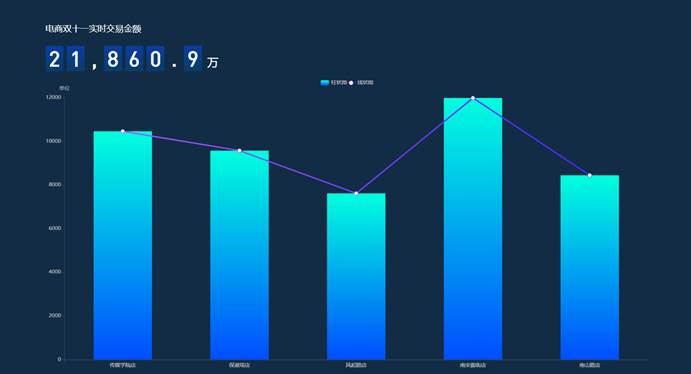
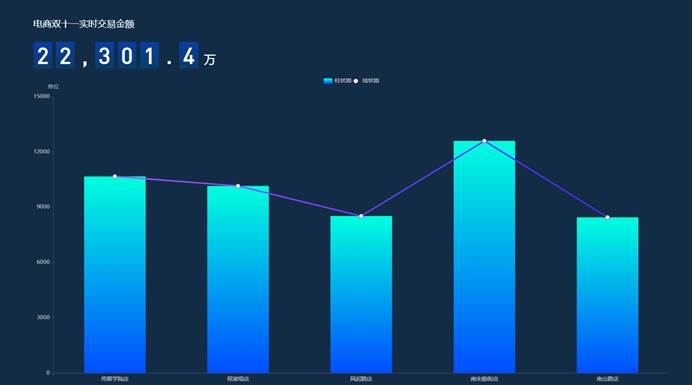
4.实验总结
(1)实验完成情况
实验完成率:100%。
(2)出现的问题与解决方案
问题1:查找Zookeeper的IP时,Zookeeper的ip有三个,不知道要用哪个。

解决:使用两个node-master里面的其中一个IP即可
问题1:对于linux命令不太熟悉。
解决:查找“菜鸟教程”或者命令行下直接在命令末尾“- - h”查看帮助。
问题2:Putty没有显示菜单键,无法duplicate session
解决:重新开启一个Putty,登录相同IP