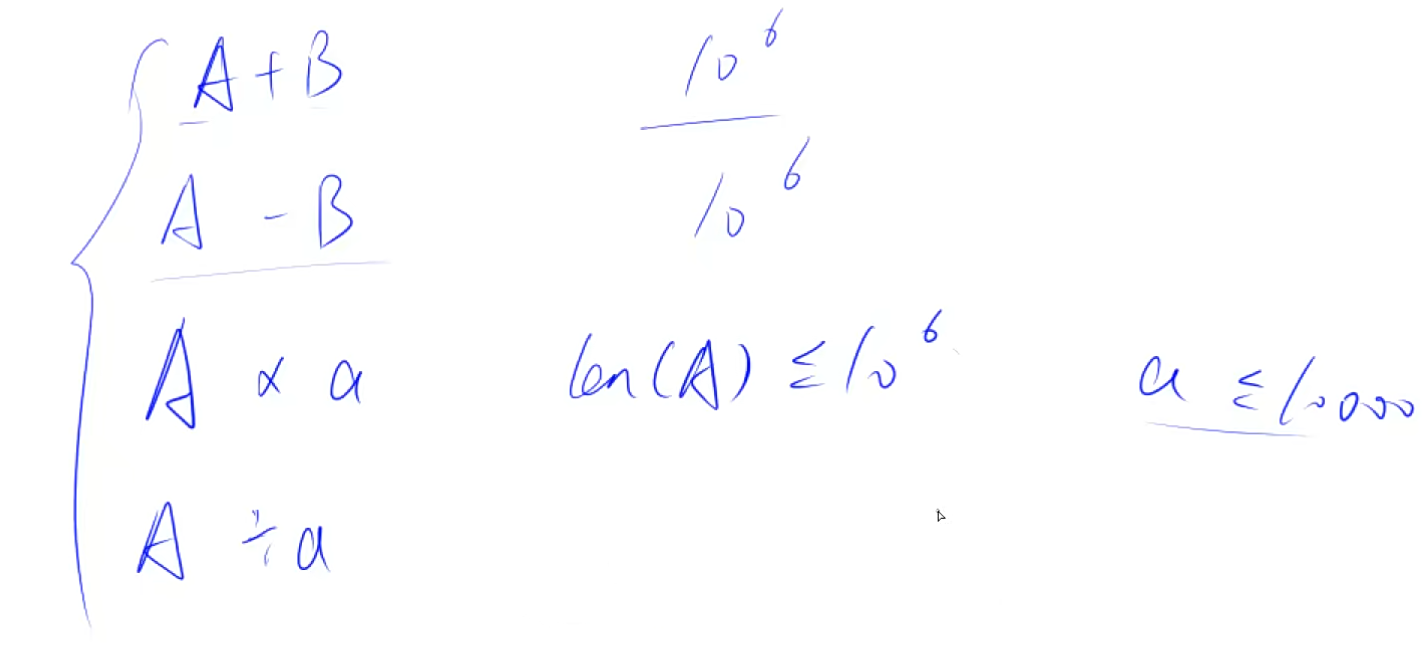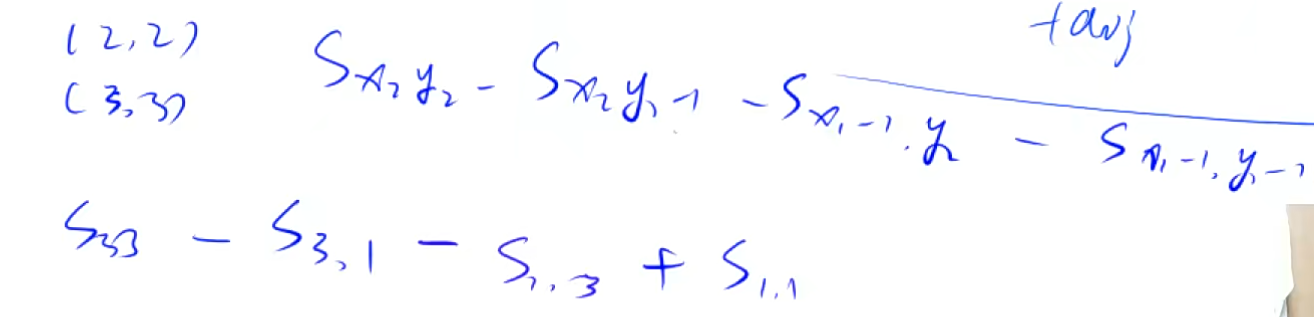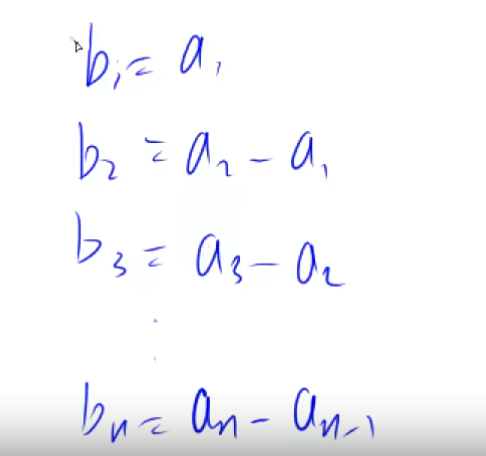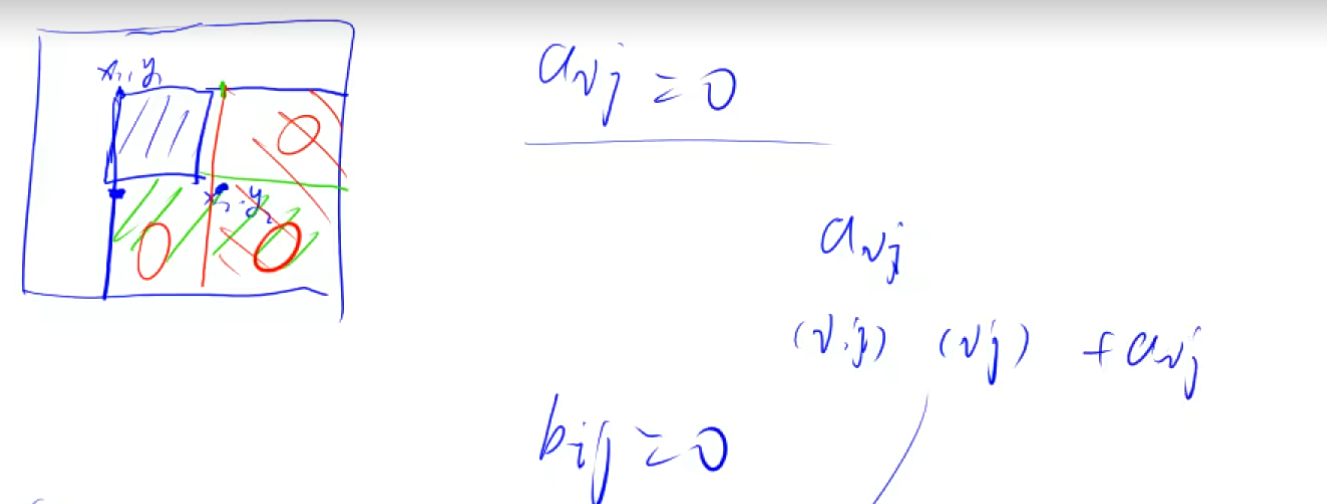#include<iostream> #include<vector>//vector自带size()函数表示数组的长度,我们就不需要开一个额外的变量去存储 了 usingnamespace std; constint N = 1e5 + 10; // A < B,返回false // A >= B,返回true
boolcmp(vector<int> &A, vector<int> &B) { if (A.size() < B.size()) returnfalse; elseif (A.size() > B.size()) returntrue; else { for (int i = A.size() - 1; i >= 0; i--) { if (A[i] > B[i]) { returntrue; // break; } elseif (A[i] < B[i]) returnfalse; else ; } } returntrue; } vector<int> sub(vector<int> &A, vector<int> &B) { // 加引用是为了提高效率.如果不加引用 的话,他会把这两个数组copy一遍,花时间 // 加引用就不拷贝,效率高 vector<int> C; int t = 0; for (int i = 0; i < A.size() || i < B.size(); i++) { if (i < A.size()) t += A[i]; if (i < B.size()) t -= B[i]; if (t < 0) { t += 10; C.push_back(t); t = -1; } else { C.push_back(t); t = 0; } }
return C; } intmain(void) { string a, b; // 用字符串读进来,存到vector里面去 vector<int> A, B; cin >> a >> b; // 读完之后 a = "123456"这样的形式 for (int i = a.size() - 1; i >= 0; i--) { A.push_back(a[i] - '0'); } // A = [6, 5, 4, 3, 2, 1]' for (int j = b.size() - 1; j >= 0; j--) { B.push_back(b[j] - '0'); } // 这里直接用compare来比较两个vector<int>类型就行了,不用自己写函数比较 if (cmp(A, B)) { auto C = sub(A, B); // 前面连续的0要略过去 int i = C.size() - 1; for (; i > 0; i--)//最后一个数,不管是不是0都要输出了. { if (C[i] != 0) break; } for (; i >= 0; i--) {
printf("%d", C[i]); } } else { auto C = sub(B, A); cout << "-"; // 前面连续的0要略过去 int i = C.size() - 1; for (; i > 0; i--) { if (C[i] != 0) break; } for (; i >= 0; i--) {
printf("%d", C[i]); } } return0; }
对这段代码的理解
1 2 3 4 5 6 7 8 9 10 11 12
// 前面连续的0要略过去 int i = C.size() - 1; for (; i > 0; i--)//最后一个数,不管是不是0都要输出了. { if (C[i] != 0) break; } for (; i >= 0; i--) {
#include<iostream> #include<vector>//vector自带size()函数表示数组的长度,我们就不需要开一个额外的变量去存储 了 usingnamespace std; constint N = 1e5 + 10; // A < B,返回false // A >= B,返回true
boolcmp(vector<int> &A, vector<int> &B) { if (A.size() < B.size()) returnfalse; elseif (A.size() > B.size()) returntrue; else { for (int i = A.size() - 1; i >= 0; i--) { if (A[i] > B[i]) { returntrue; // break; } elseif (A[i] < B[i]) returnfalse; else ; } } returntrue; } vector<int> sub(vector<int> &A, vector<int> &B) { // 加引用是为了提高效率.如果不加引用 的话,他会把这两个数组copy一遍,花时间 // 加引用就不拷贝,效率高 vector<int> C; int t = 0; for (int i = 0; i < A.size() || i < B.size(); i++) { if (i < A.size()) t += A[i]; if (i < B.size()) t -= B[i]; if (t < 0) { t += 10; C.push_back(t); t = -1; } else { C.push_back(t); t = 0; } }
return C; } intmain(void) { string a, b; // 用字符串读进来,存到vector里面去 vector<int> A, B; cin >> a >> b; // 读完之后 a = "123456"这样的形式 for (int i = a.size() - 1; i >= 0; i--) { A.push_back(a[i] - '0'); } // A = [6, 5, 4, 3, 2, 1]' for (int j = b.size() - 1; j >= 0; j--) { B.push_back(b[j] - '0'); } // 这里直接用compare来比较两个vector<int>类型就行了,不用自己写函数比较 if (cmp(A, B)) { auto C = sub(A, B); // 前面连续的0要略过去 int i = C.size() - 1; for (; i >= 0; i--) { if (C[i] != 0) break; } // 去掉前面所有连续的零 if (i >= 0) // 遇到了第一个非零数 for (; i >= 0; i--) {
printf("%d", C[i]); } else// 没遇到非零数,也就是所有数都是零 cout << 0; } else { auto C = sub(B, A); cout << "-"; // 前面连续的0要略过去 int i = C.size() - 1; for (; i >= 0; i--) { if (C[i] != 0) break; } // 去掉前面所有连续的零 if (i >= 0) // 遇到了第一个非零数 for (; i >= 0; i--) {
#include<iostream> #include<vector>//vector自带size()函数表示数组的长度,我们就不需要开一个额外的变量去存储 了 usingnamespace std; constint N = 1e5 + 10; // A < B,返回false // A >= B,返回true
boolcmp(vector<int> &A, vector<int> &B) { if (A.size() < B.size()) returnfalse; elseif (A.size() > B.size()) returntrue; else { for (int i = A.size() - 1; i >= 0; i--) { if (A[i] > B[i]) { returntrue; // break; } elseif (A[i] < B[i]) returnfalse; else ; } } returntrue; } vector<int> sub(vector<int> &A, vector<int> &B) { // 加引用是为了提高效率.如果不加引用 的话,他会把这两个数组copy一遍,花时间 // 加引用就不拷贝,效率高 vector<int> C; int t = 0; for (int i = 0; i < A.size() || i < B.size(); i++) { if (i < A.size()) t += A[i]; if (i < B.size()) t -= B[i]; if (t < 0) { t += 10; C.push_back(t); t = -1; } else { C.push_back(t); t = 0; } }
return C; } intmain(void) { string a, b; // 用字符串读进来,存到vector里面去 vector<int> A, B; cin >> a >> b; // 读完之后 a = "123456"这样的形式 for (int i = a.size() - 1; i >= 0; i--) { A.push_back(a[i] - '0'); } // A = [6, 5, 4, 3, 2, 1]' for (int j = b.size() - 1; j >= 0; j--) { B.push_back(b[j] - '0'); } // 这里直接用compare来比较两个vector<int>类型就行了,不用自己写函数比较 if (cmp(A, B)) { auto C = sub(A, B); // 前面连续的0要略过去 int i = C.size() - 1; for (; i > 0; i--) // 最后一个数,不管是不是0都要输出了. { if (C[i] != 0) break; } if (i > 0) for (; i >= 0; i--) {
printf("%d", C[i]); } else { if (i == 0 && C[0] != 0) for (; i >= 0; i--) {
printf("%d", C[i]); } elseif (i == 0 && C[0] == 0) for (; i >= 0; i--) {
printf("%d", C[i]); } } } else { auto C = sub(B, A); cout << "-"; // 前面连续的0要略过去 int i = C.size() - 1; for (; i > 0; i--) // 最后一个数,不管是不是0都要输出了. { if (C[i] != 0) break; } if (i > 0) for (; i >= 0; i--) {
printf("%d", C[i]); } else { if (i == 0 && C[0] != 0) for (; i >= 0; i--) {
printf("%d", C[i]); } elseif (i == 0 && C[0] == 0) for (; i >= 0; i--) {
constint N = 100010; vector<int> mul(vector<int> &A, int b); intmain(void) { string a; int b; cin >> a >> b; vector<int> A; for (int i = a.size() - 1; i >= 0; i--) A.push_back(a[i] - '0');
auto C = mul(A, b); for (int i = C.size() - 1; i >= 0; i--) printf("%d", C[i]); return0; } vector<int> mul(vector<int> &A, int b) { // 先尝试自己写 vector<int> C; int t = 0; // 这里i < A.size() || t你用我之前的true和false分别分四种情况看一看就能理解了 for (int i = 0; i < A.size() || t; i++) { if (i < A.size()) t += A[i] * b; C.push_back(t % 10); t /= 10; }
#include<iostream> usingnamespace std; constint N = 100010; int n, m; int a[N], b[N]; intmain(void) { scanf("%d %d", &n, &m); for (int i = 1; i <= n; i++) { scanf("%d", &a[i]); } // 构造差分数组 for (int i = 1; i <= n; i++) { b[i] = a[i] - a[i - 1]; } while (m--) { int l, r, c; scanf("%d %d %d", &l, &r, &c);
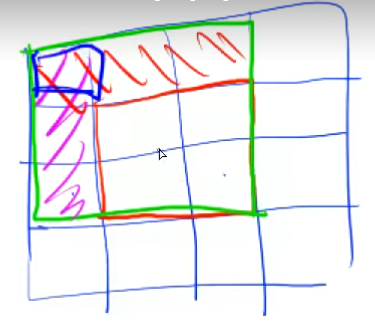
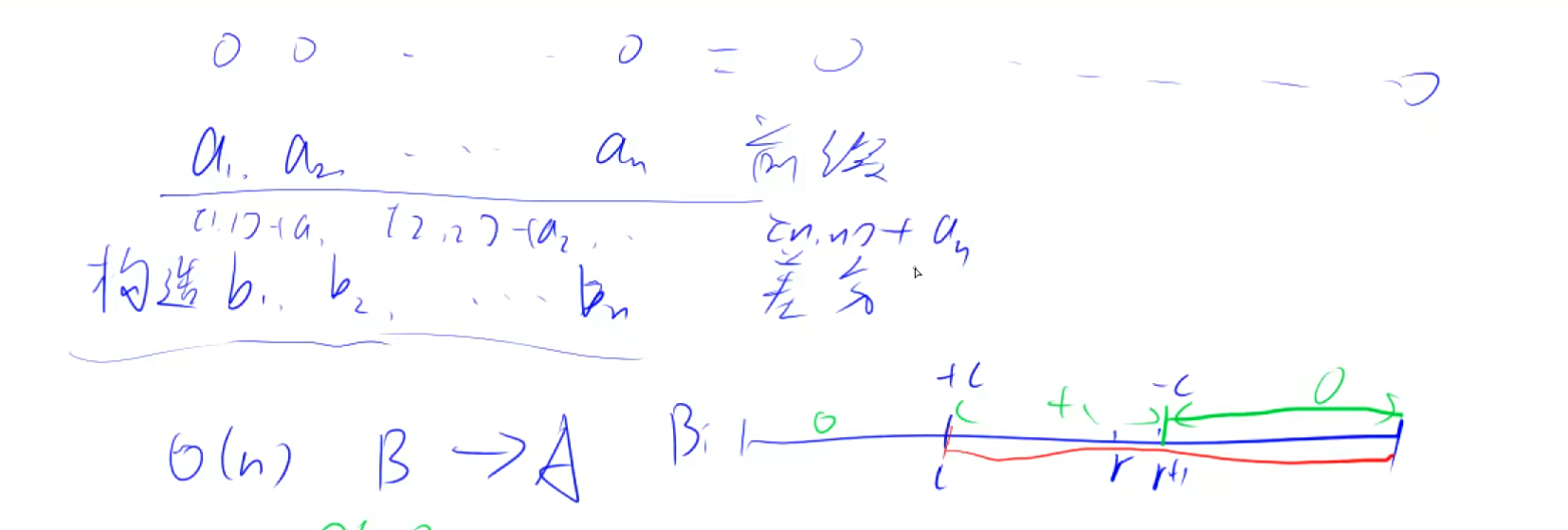
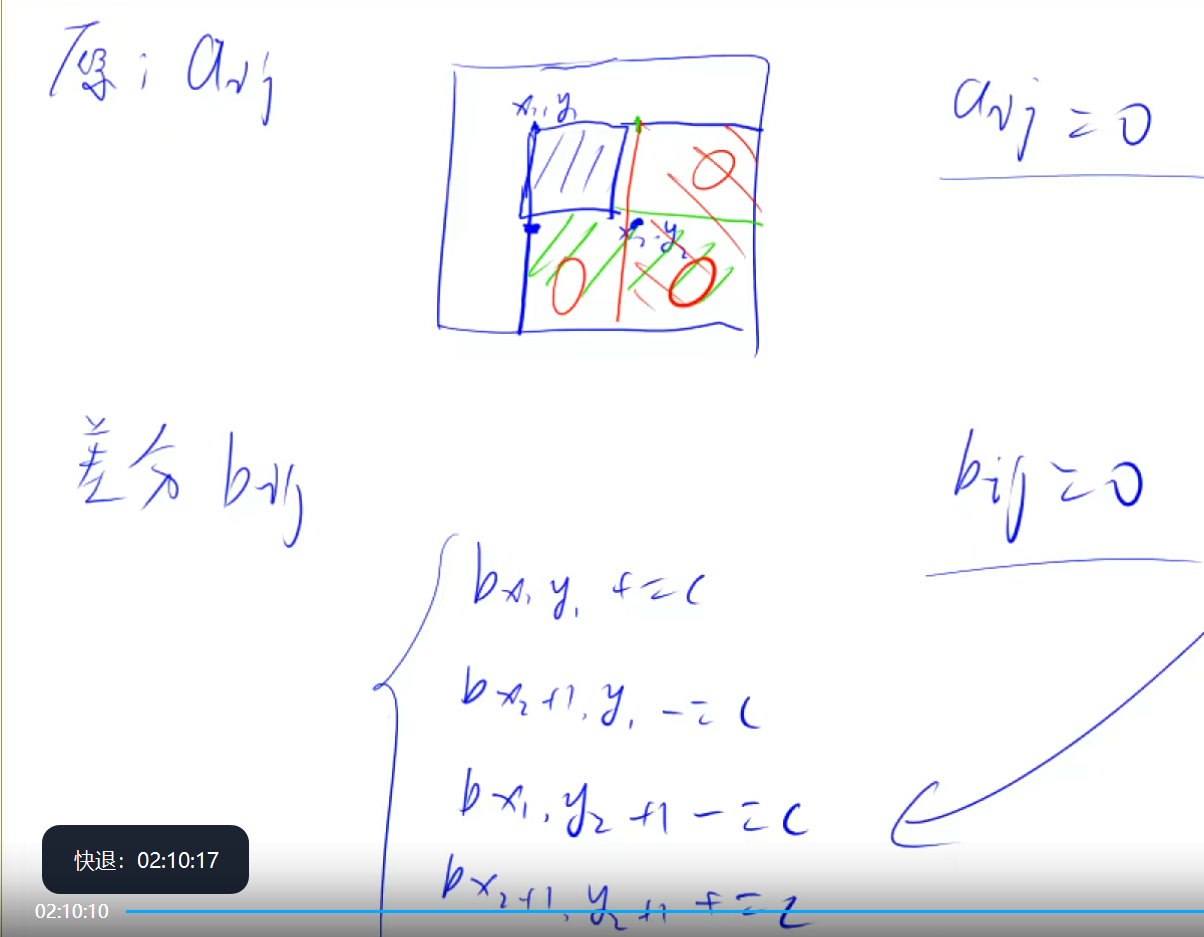
constint N = 1010; int n, m, q; int a[N][N], b[N][N]; voidinsert(int x1, int y1, int x2, int y2, int c) { b[x1][y1] += c; b[x1][y2 + 1] -= c; b[x2 + 1][y1] -= c; b[x2 + 1][y2 + 1] += c; } intmain(void) { scanf("%d %d %d", &n, &m, &q); for (int i = 1; i <= n; i++) for (int j = 1; j <= m; j++) scanf("%d", &a[i][j]);
for (int i = 1; i <= n; i++) for (int j = 1; j <= m; j++) insert(i, j, i, j, a[i][j]);
while (q--) { int x1, y1, x2, y2, c; scanf("%d %d %d %d %d", &x1, &y1, &x2, &y2, &c); insert(x1, y1, x2, y2, c); } for (int i = 1; i <= n; i++) for (int j = 1; j <= m; j++) b[i][j] = b[i][j] + b[i - 1][j] + b[i][j - 1] - b[i - 1][j - 1]; for (int i = 1; i <= n; i++) { for (int j = 1; j <= m; j++) printf("%d ", b[i][j]); printf("\n"); } return0; }
constint N = 1010; int n, m, q; int a[N][N], b[N][N]; voidinsert(int x1, int y1, int x2, int y2, int c) { b[x1][y1] += c; b[x1][y2 + 1] -= c; b[x2 + 1][y1] -= c; b[x2 + 1][y2 + 1] += c; } intmain(void) { scanf("%d %d %d", &n, &m, &q); for (int i = 1; i <= n; i++) for (int j = 1; j <= m; j++) scanf("%d", &a[i][j]);
for (int i = 1; i <= n; i++) for (int j = 1; j <= m; j++) insert(i, j, i, j, a[i][j]);
while (q--) { int x1, y1, x2, y2, c; scanf("%d %d %d %d %d", &x1, &y1, &x2, &y2, &c); insert(x1, y1, x2, y2, c); } for (int i = 1; i <= n; i++) for (int j = 1; j <= m; j++) b[i][j] = b[i][j] + b[i - 1][j] + b[i][j - 1] - b[i - 1][j - 1]; for (int i = 1; i <= n; i++) { for (int j = 1; j <= m; j++) printf("%d ", b[i][j]); printf("\n"); } return0; }
所以可以发现差分的核心就是这个insert函数
1 2 3 4 5 6 7
voidinsert(int x1, int y1, int x2, int y2, int c) { b[x1][y1] += c; b[x1][y2 + 1] -= c; b[x2 + 1][y1] -= c; b[x2 + 1][y2 + 1] += c; }